一些计算机视觉任务会依赖图像的几何关系,比如相机定位,三维重建等等。一种方法用于求解图像的几何关系是通过图像局部特征的相关匹配来求解。图像的局部特征则是从图像局部区域中抽取的特征,包括边缘、角点、线、曲线和特别属性的区域等。一般来说,图像的局部特征包含两个部分,局部特征点的位置,局部特征的描述符。在一方面上,描述符可分为基于人工的特征符和基于学习的特征符。
文本将关注于在特征点已知的情况下,如何通过学习去生成描述符去描述局部区域(Patch)的。相较于网络架构,本文主要关注于不同论文的数据处理和学习策略。
数据和任务
基本Patch的描述符(local descriptor)即给定Patch生成local descriptor。对于神经网络来说,即意味着网络的输入是图像局部区域(Patch),网络的输出是该Patch的特征。
其中图像局部区域(Patch)是基于图像的特征点所提取的的。如下图所示,下面五个图像来自于同一场景,图上的圆圈的中心即是特征点,而圆圈所选择的区域即是Patch。

需要注意的是,由于五个图像来自于同一场景,图像中的特征点也一一匹配。如下图所示,下图的每一列都是从匹配的特征点所提取的局部区域,而每一行则代表了从每幅图像所提取的全部Patch。

理想的描述符(local descriptor)是使得匹配的特征点的描述符一致或距离相近,不匹配的特征点的描述符距离较远。对应于上图,即每一列样本之间的描述符应距离相近,而每一行的样本之间的描述符应距离较远。
在数学上,假设有一特征点 A,其描述符标为 a,称之参考样本或锚点(anchor)。与之匹配的特征点 P 可被称为正样本(positive sample),其描述符标为 p。与之不匹配的特征点 N 可被称为负样本(negative sample),其描述符标为 n。理想情况下,参考样本与正样本之间的距离应远小于参考样本与负样本之间的距离:
训练流程
对于基本Patch的描述符(local descriptor),一个常见的训练流程如下图所示。
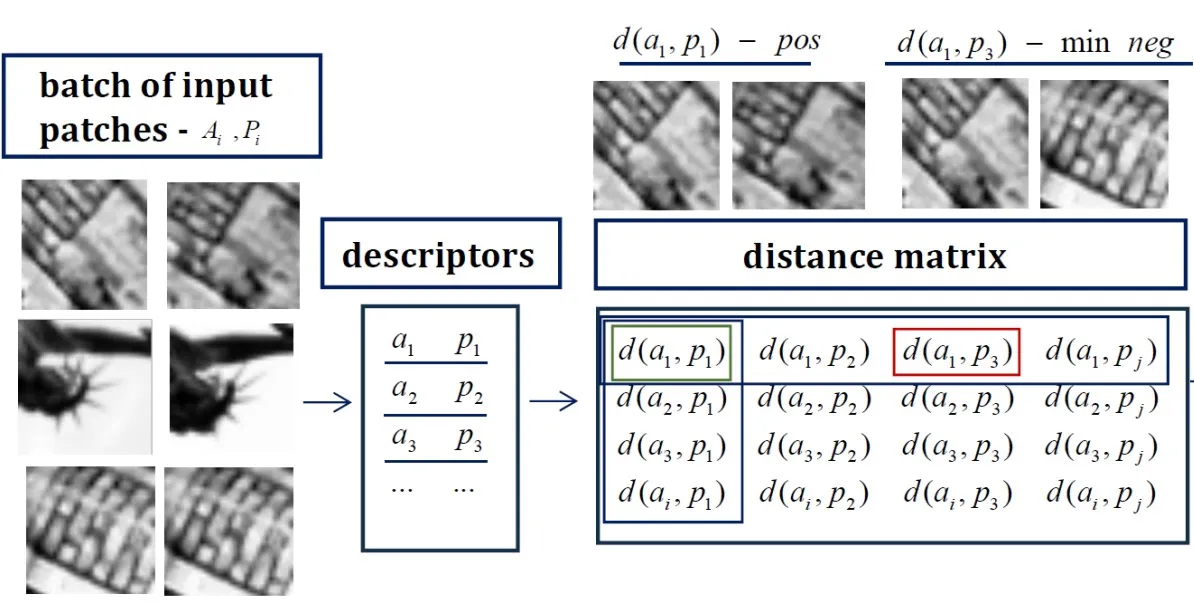
数据采样
具体而言,随机选取 n 对匹配的 patches 组成最终的 training batch,所以最终的 training batch 为:
其中 (Ai, Pi) 表示对应的一对匹配的 patch 对。
描述子和距离矩阵
通过神经网络,可以生成样本 (Ai, Pi) 所对应的描述子 (ai, pi)。针对于同一 batch 中的参考样本和正样本俩俩组合计算距离,可得到上图右侧所示的距离矩阵。当组合的参考样本和正样本匹配时,则该距离为正样本距离,不匹配时,则该距离为负样本样本距离。
对于描述子和距离矩阵,可采用不同的损失函数,进而学习网络。
学习策略
L2Net | L2-Net: Deep Learning of Discriminative Patch Descriptor in Euclidean Space
L2Net是相对早期的Patch-Based基于深度学习的描述符。其损失函数基本已不再使用,但其模型直至现在仍被广泛使用。
L2Net损失函数主要分为三个部分:
- Error term for descriptor similarity:利用相对距离区分匹配上和未匹配上的 patch pairs,即在距离矩阵的行和列上求softmax;
- Error term for descriptor compactness:考虑最后输出特征向量的 compactness,也就是特征向量的各个维度尽可能不相关。即在相关矩阵上加penalty;
- Error term for intermediate feature maps:学习过程中间的 feature maps 进行额外的监督,可以得到更好的性能。即求每个中间层的距离矩阵,并在该距离矩阵的行和列上求softmax。
L2Net模型如下图所示。L2Net采用单路全卷积框架,图中3x3 Conv代表Conv+BN+Relu,8×8 Conv代表Conv+BN,在第三层和第五层的卷积层步长为2用于下采样。LRN(Local Response Normalization layer)用于归一化输出,等价于L2Norm。需要注意的是,由于区域图像变化较大,为了消除光照等其他因素的影响,一般也会在模型初始加InstanceNorm。
flowchart LR
Input[Patch] --> B(3x3 Conv 32):::Conv
B --> C(3x3 Conv 32):::Conv
C --> D(3x3 Conv 64/2):::ConvDown
D --> E(3x3 Conv 64):::Conv
E --> F(3x3 Conv 128/2):::ConvDown
F --> G(3x3 Conv 128):::Conv
G --> H(8x8 Conv 128):::ConvBN
H --> J(LRN):::LRN
J --> Descriptor(Descriptor)
classDef Conv fill:#cfc;
classDef ConvDown fill:#cff;
classDef ConvBN fill:#ffc;
classDef LRN fill:#fcc;该网络简单直接,特征提取速度在ms级,在低端gpu上基本在1ms左右。
HardNet | Working hard to know your neighbor’s margins: Local descriptor learning loss
HardNet的训练流程如下图所示。
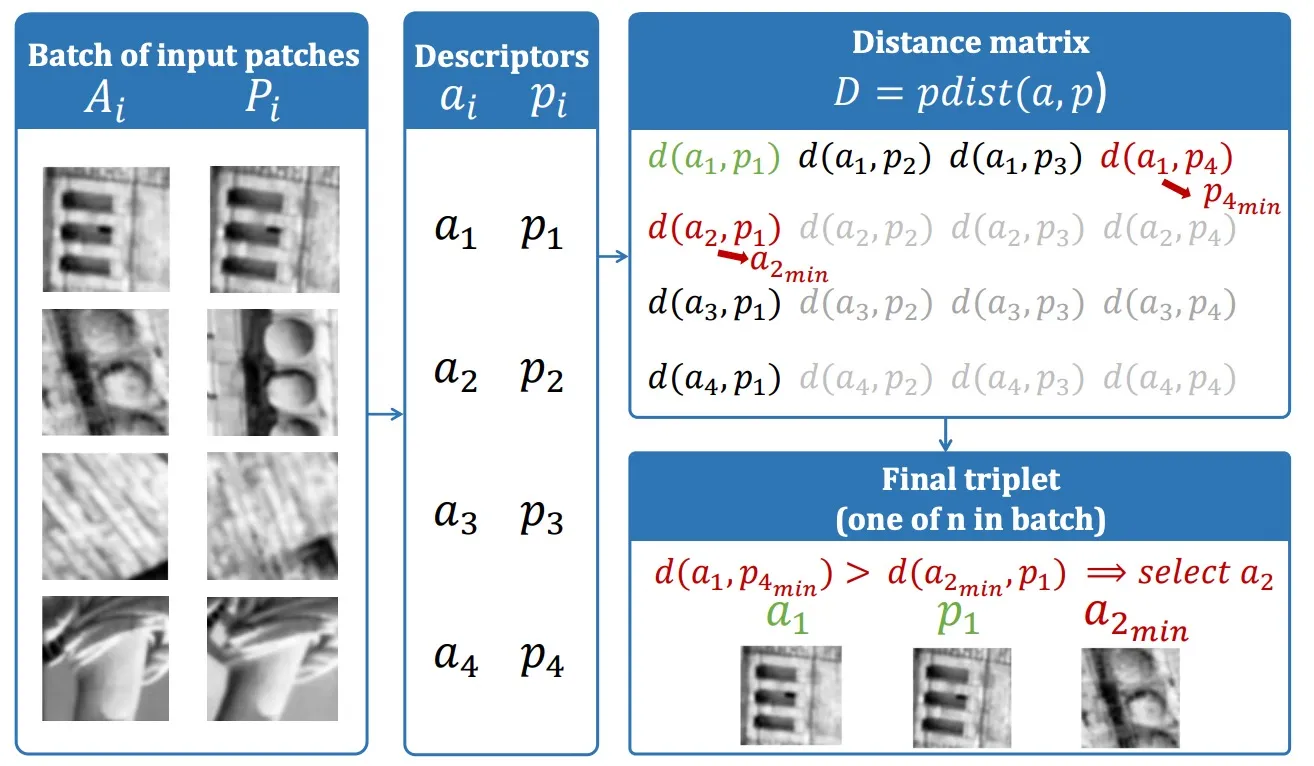
简单而讲,HardNet采用了度量学习中的triplet loss去最大化training batch中正负样本之间的距离。
具体而言,当距离矩阵已知时,对于匹配的Patch对,可以找到:
- ai: anchor 描述符
- pi: positive 描述符
- pjmin: 表示距离 ai 最近的非匹配描述符,在上图中对应 p4
- akmin: 表示距离 pi 最近的非匹配描述符,在上图中对应 a2
其中两个 hard-negative 的下标定义为:
这样对于每个匹配的 patch pair 都可以生成一个四元组:
而在四元组中的距离包括:
- d(ai, pi): anchor-positive 距离
- d(ai, pjmin): anchor-negative 距离
- d(akmin, pi): anchor-negative 距离
由于最后的目标是最大化training batch中正负样本之间的距离。所以将选取最难的样本进行训练,对应于anchor-negative 距离中,即意味着距离最小的样本。因此,最终的损失函数为:
损失函数对应的代码为
def triplet_loss(x, label, margin=0.1):
# x is D x N
dim = x.size(0) # D
nq = torch.sum(label.data==-1).item() # number of tuples
S = x.size(1) // nq # number of images per tuple including query: 1+1+n
xa = x[:, label.data==-1].permute(1,0).repeat(1,S-2).view((S-2)*nq,dim).permute(1,0)
xp = x[:, label.data==1].permute(1,0).repeat(1,S-2).view((S-2)*nq,dim).permute(1,0)
xn = x[:, label.data==0]
dist_pos = torch.sum(torch.pow(xa - xp, 2), dim=0)
dist_neg = torch.sum(torch.pow(xa - xn, 2), dim=0)
return torch.sum(torch.clamp(dist_pos - dist_neg + margin, min=0)) / nqSOSNet | SOSNet: Second Order Similarity Regularization for Local Descriptor Learning
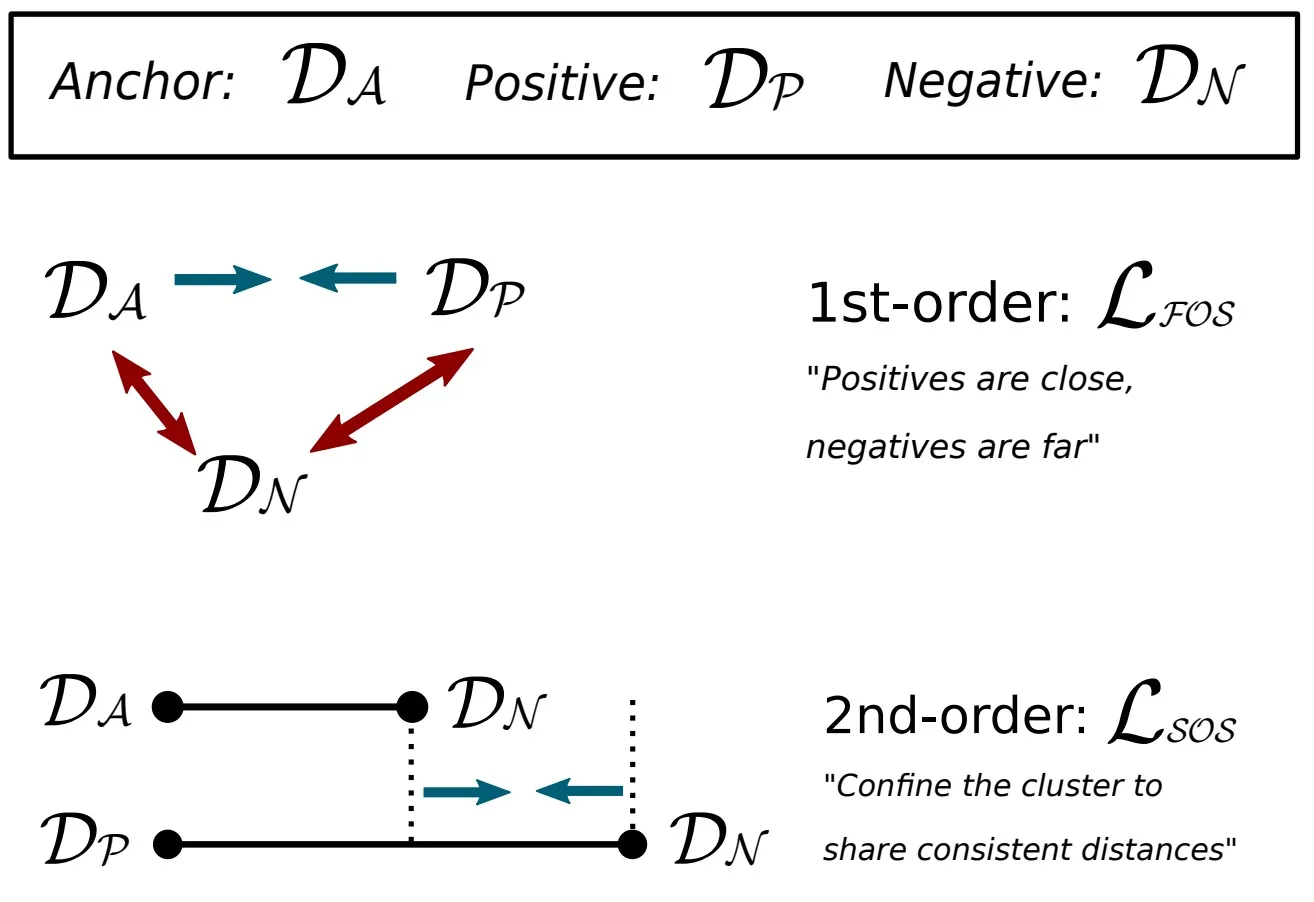
HardNet的loss是由距离度量直接组成的,其可以被认为是基于一阶相似距离的loss。SOSNet在此之上又增加了基于二阶相似距离的loss。
所谓二阶距离,这里指在如下四元组中两个 anchor-negative 距离之间的距离:
对应的二阶距离为:
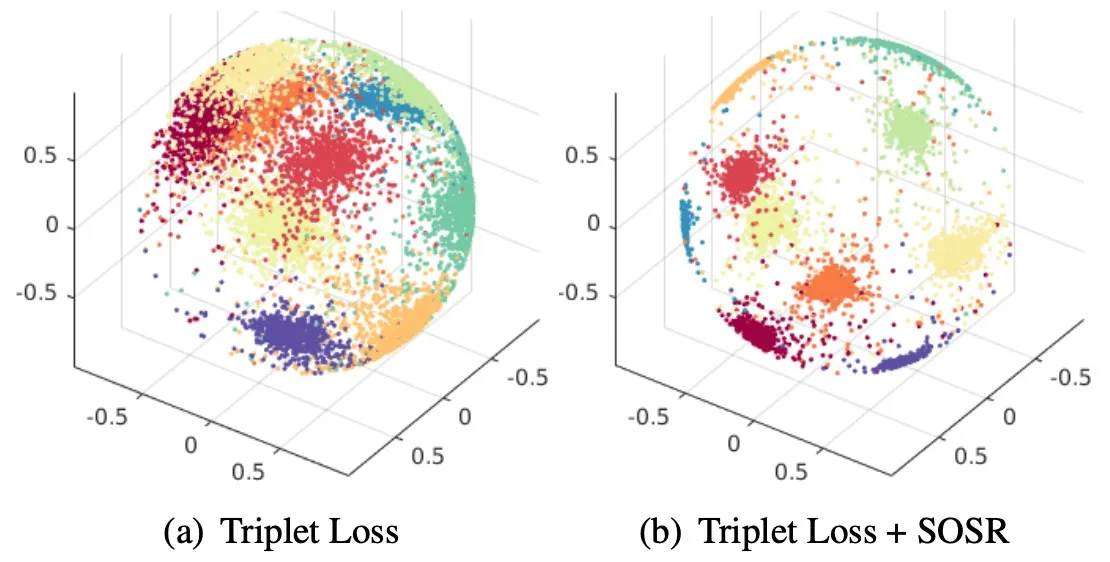
通过最小化二阶距离,可使得 local descriptor 更加聚积,如下图所示。
二阶距离损失函数对应的代码为
def sos_loss(x, label):
# x is D x N
dim = x.size(0) # D
nq = torch.sum(label.data==-1).item() # number of tuples
S = x.size(1) // nq # number of images per tuple including query: 1+1+n
xa = x[:, label.data==-1].permute(1,0).repeat(1,S-2).view((S-2)*nq,dim).permute(1,0) # D * (B * num_neg)
xp = x[:, label.data==1].permute(1,0).repeat(1,S-2).view((S-2)*nq,dim).permute(1,0)
xn = x[:, label.data==0]
dist_an = torch.sum(torch.pow(xa - xn, 2), dim=0)
dist_pn = torch.sum(torch.pow(xp - xn, 2), dim=0)
return torch.sum(torch.pow(dist_an - dist_pn, 2)) ** 0.5 / nqLog Polar Transformation | Beyond Cartesian Representations for Local Descriptors
另一篇对局部特征很有帮助的工作是Log Polar Transformation。其核心是通过在图像预处理中引入Log Polar Transformation,将图像从欧式坐标系转换为对数极坐标系表示。由于不同的旋转和尺度变化在对数极坐标系下对图像不会有太大影响,因此Log Polar Transformation会使得模型对旋转和尺度变化的鲁棒性较好。
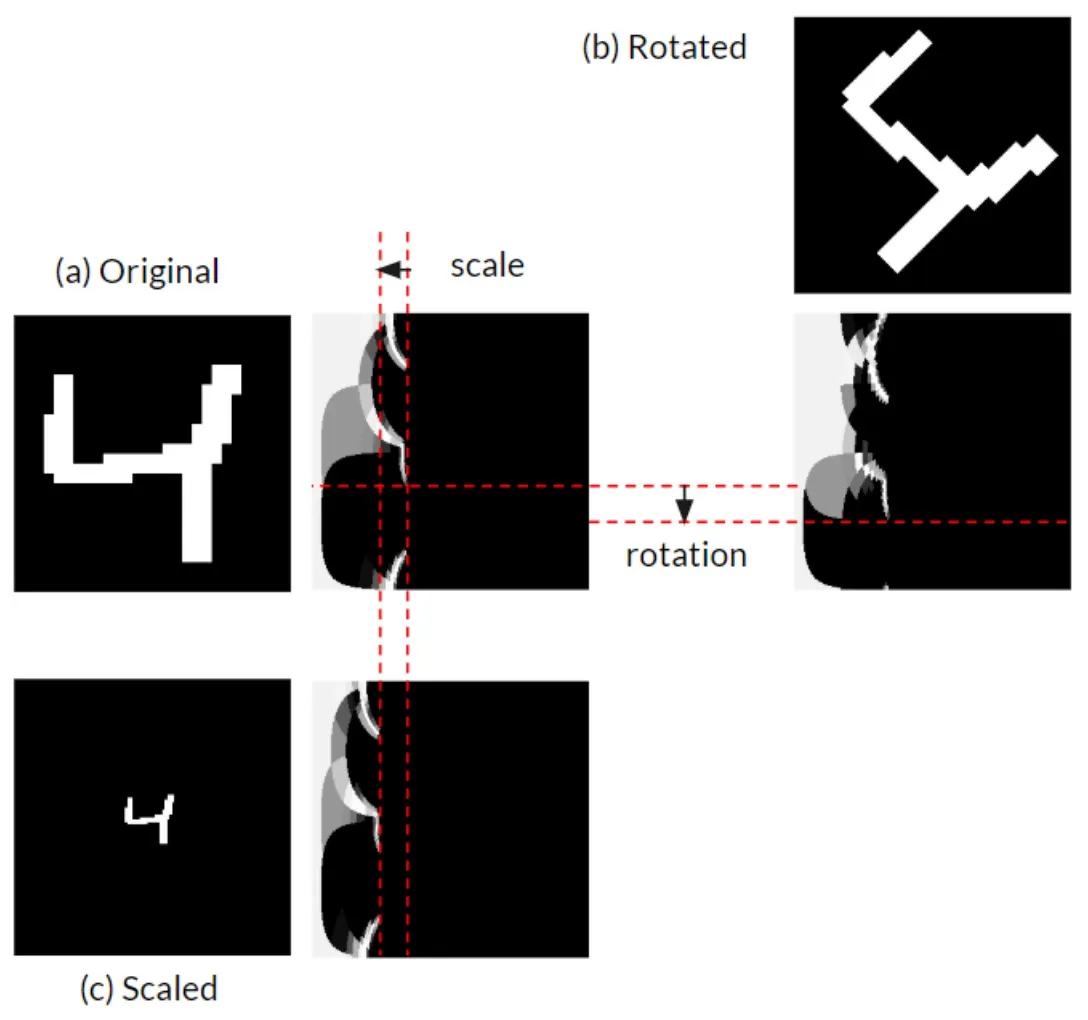
如上图所示,在欧式图像上的旋转和尺度变化对应到对数极坐标系下是竖直和水平方向上的平移变化。而卷积操作的滑动窗口计算方式使得其对平移变化非常鲁棒。需要注意的是,由于一般Patch-based卷积神经网络都非常浅,导致其无法很好的消除由旋转的尺度变化所导致的偏差。甚至为了消除这种偏差,在工程上常常使用重力的方向来旋转输入CNN的Patch。因此,Log Polar Transformation通过增强模型对旋转和尺度变化的鲁棒性,进而提升了模型的鲁棒性和准确度。
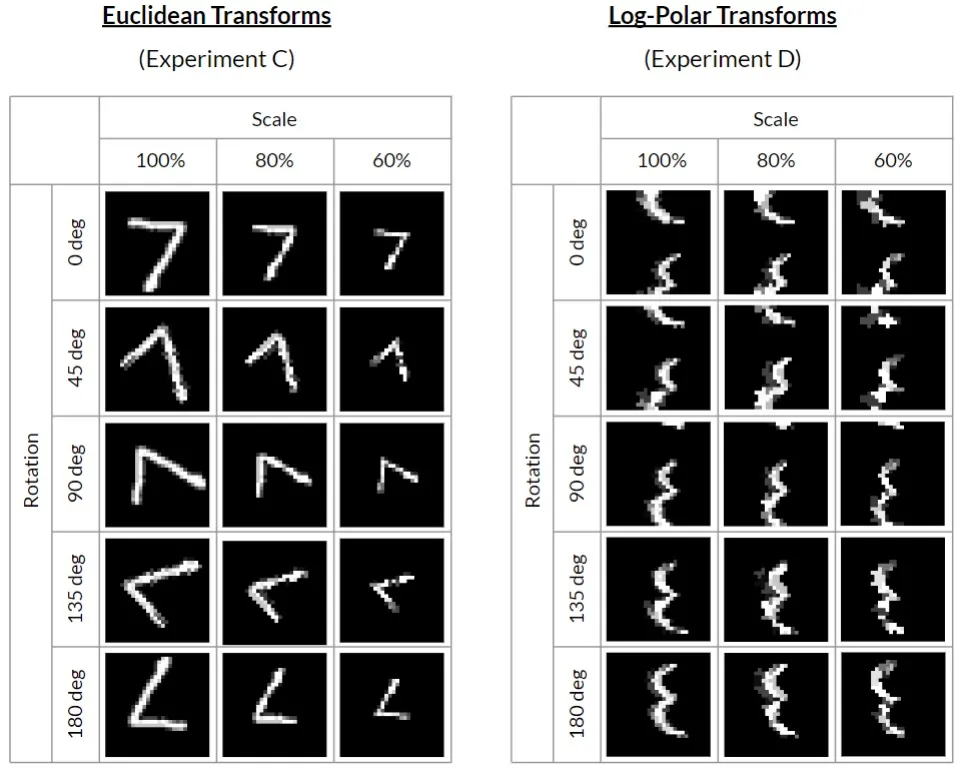
更多的旋转和尺度变化在对欧式坐标系和对数极坐标系的表现如下图所示。
Log Polar Transformation在图像预处理时可以实现为
def to_log_polar(img, dsize, max_radius):
assert isinstance(img, Image.Image)
# dsize = img.size
center = [s // 2 for s in img.size]
flags = cv2.WARP_POLAR_LOG
out = cv2.warpPolar(
np.asarray(img), dsize=dsize, center=center, maxRadius=max_radius, flags=flags
)
return Image.fromarray(out)
def from_log_polar(polar_img, dsize, max_radius):
assert isinstance(polar_img, Image.Image)
# dsize = polar_img.size
center = [s // 2 for s in polar_img.size]
flags = cv2.WARP_POLAR_LOG | cv2.WARP_INVERSE_MAP
out = cv2.warpPolar(
np.asarray(polar_img),
dsize=dsize,
center=center,
maxRadius=max_radius,
flags=flags,
)
return Image.fromarray(out)需要注意的是由于pytorch GridSample 的计算方式不同,用opencv实现的log polar transform会与论文原始PTN网络输出不一致,对于原始PTN网络实现可以参考论文代码。
参考
- L2-Net: Deep Learning of Discriminative Patch Descriptor in Euclidean Space
- Working hard to know your neighbor’s margins: Local descriptor learning loss
- SOSNet: Second Order Similarity Regularization for Local Descriptor Learning
- Beyond Cartesian Representations for Local Descriptors
- Human eye inspired log-polar pre-processing for neural networks